

In the first two posts of this series we looked at what could possibly go wrong when we tried to connect a service designed to face the Internet, to not one, not many, but lots of customers’ wide area networks (WANs). We learned that NAT was a great tool, but that it was only part of the solution. We also learned that to connect two networks which use the same addresses, we need an intermediate set of addresses to hide the two networks from each other. In this post, we’ll find some suitable addresses for that intermediate stage, and look at the scaling of this model for multiple customers connecting to multiple services.
Let’s just recap a couple of the points from that last paragraph in pictures, as it will set us up nicely to design a working solution. First, in the picture below, we’re using a single routing device / Gateway to both NAT packets and interconnect the various networks. This would be convenient for a Provider as they could manage all this complex networking malarkey in one place, except we learned in the last post that this won’t work. The reason was that, although NAT swaps from (potentially overlapping) customer networks to something coordinated by the Provider, on the way back, when we (un)NAT back to real addresses, that single routing device needs to send the packets back to the correct customer network which it can’t do when faced with multiple ‘10.1.1.1s’ in different customer networks! The red circle is the gateway’s view into all the connected networks and their potentially overlapping address ranges.
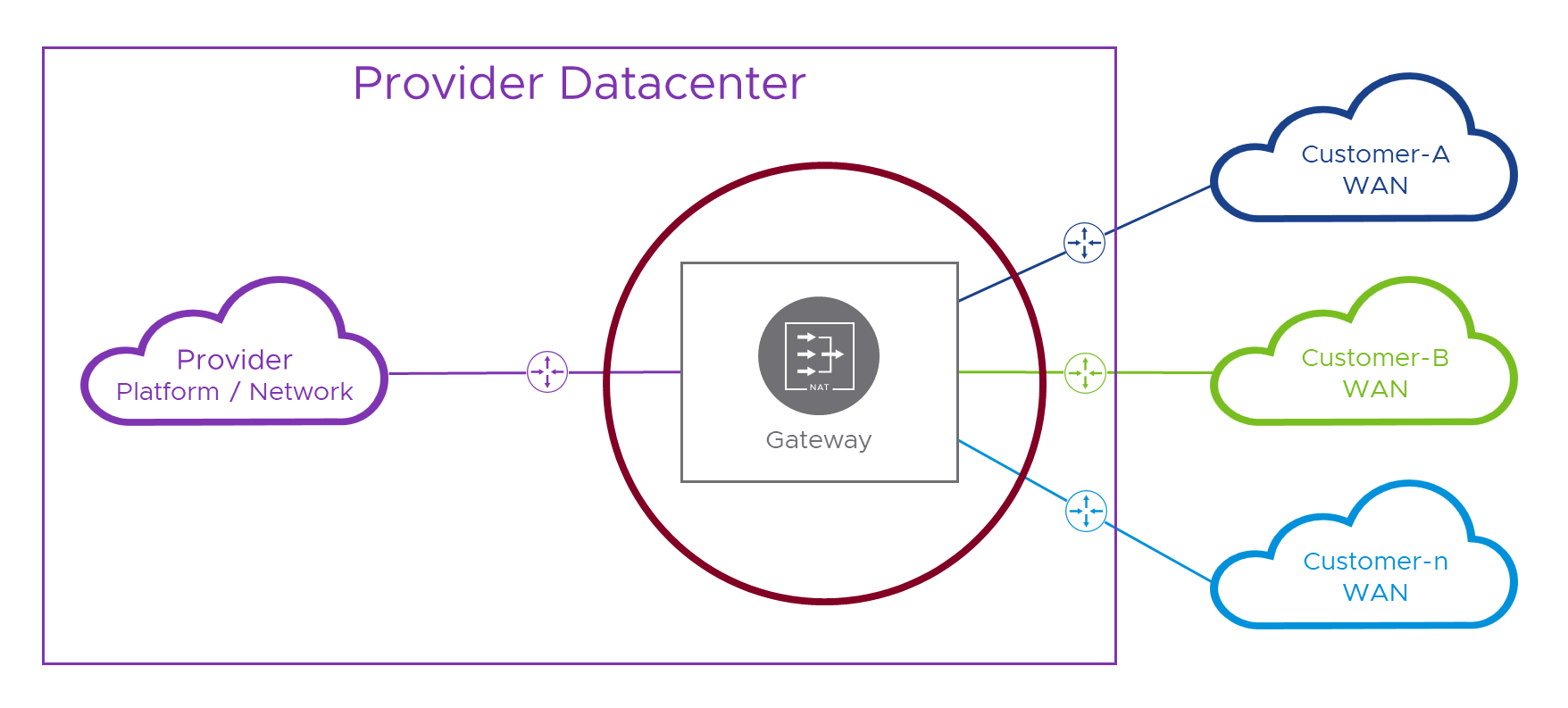
In order to overcome that problem, we need to make sure that, by the time we’re un-NATing the packet back to its real addresses, the routing/(un)NATing device only sees one pesky ‘10.1.1.1’. In practice, this means we have to route to a per-customer NATing device before we lose track of which customer we’re trying to get to. That means we need a solution like this, with that stupid lake from the last post replaced by some real networking which for now we’ll color orange and call intermediate network (or “lake” for short ).
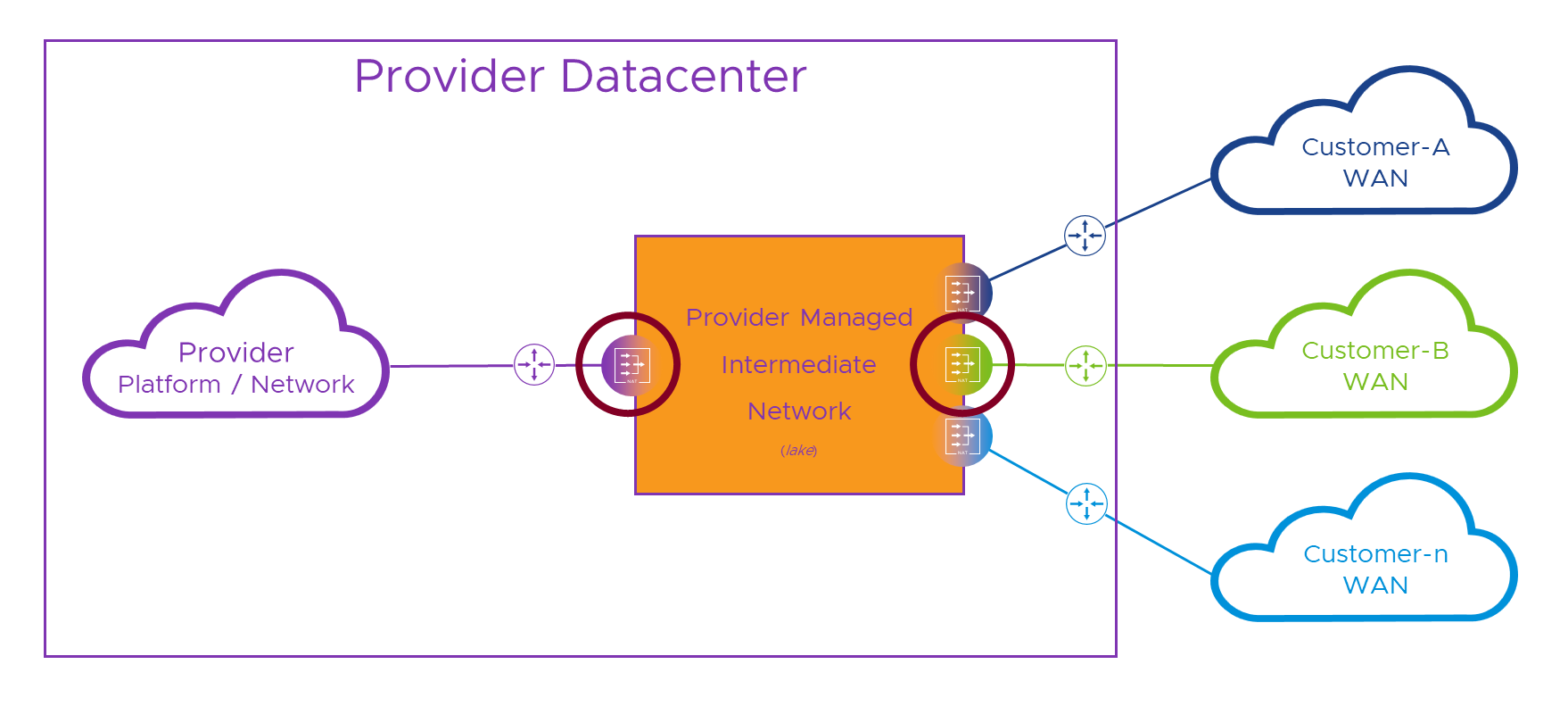
In the diagram above, whichever way we’re crossing the intermediate network, we hide our real addresses behind temporary intermediate addresses (lake was way shorter to type.. just sayin’…) and make our routing decision by sending the traffic to the intermediate network address of the destination NAT device. Once we’re safely in the NAT device for the destination network, we can dump ( un-NAT) our temporary intermediate addresses and set off across the destination network as if nothing happened. This time, where the red circles cross networks, each NAT device can see only its connected network and the shared intermediate one.
Think of the network packet like Tom Cruise leaving the IMF safe house and running through a crowded eastern European city. Dashing into the (equally crowded) railway station, pausing just long enough to rip off his false rubber nose and “I’m in disguise” glasses, before nonchalantly boarding the 14:10 to Paris Gare du Nord and heading to the restaurant car to order a fine Chablis. All, while the MI(longINT) theme music starts to play. Anyhoo, I digress (and wine would make the packets all soggy), so back to the network stuff…
In that last diagram, even if multiple customers and/or the Provider use the same addresses anywhere in their networks, no single device will see more than one of them. The only other thing the NAT devices will need to connect to, is the intermediate network and its addresses. In the first post when we contrived to make the solution work (impractically) by not having any addresses overlap between the various networks, we saw how choosing ‘10.1.1.x’ would be a bad idea because everybody else was likely to choose it somewhere in their network too. In all seriousness (okay, just briefly), where do we get addresses that will work for our intermediate network and not clash with any customer network..?
To bravely choose what nobody chose before
There are three subnets reserved in our old friend rfc1918. There’s ‘192.168.0.0/16’ (or ‘192.168.x.x’) which we often find in consumer level networking devices. Then there’s the more industrial strength ‘10.0.0.0/8’ (or ‘10.x.x.x’) which we often see in enterprise and Service Provider networks. The third subnet it slightly different and not so easy to simply drop ‘x’ into. It’s ‘172.16.0.0/12’. As the slash-twelve doesn’t fall nicely on an octet boundary like slash-eight and slash-sixteen, this range is ‘172.16.x.x’, ‘172.17.x.x’ all the way up to ‘172.31.x.x’. The subnets from ‘172.32.x.x’ upwards aren’t included in the reserved range so shouldn’t be used in private networks. According to the ARIN search below, ‘172.32(.x.x)-172.63’ belongs to T-Mobile US, and if we bothered to search further, we’d find out who the rest of the range belongs to.
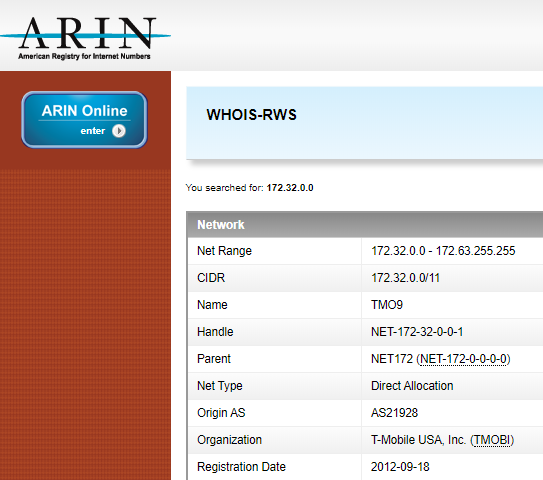
That said, there are corporate networks out there I’m sure, who allocated ‘172.(16-31).x.x’ to their remote locations and carried on through ‘172.32.x.x’ and beyond. We should keep this in mind whenever we plan for addresses customers might use.
We could choose some addresses from RFC1918 and hope nobody else is using them, but that’s not exactly something we want to put our name against in the project Risk Register! What we need are some IP addresses that nobody is (or at least should be) using in their network and that’s big enough to scale to allow for many, or even lots, of customers. What we really need are some special IPv4 addresses.
Checking out the IANA table in (conveniently) that link, it turns out that there are a bunch of special ranges, included in which, are a couple of likely candidates we can potentially use.
Let’s take a look at a couple from the IANA IPv4 Special Registery!
| Address Block | Name | RFC | Term’n Date | SRC | DST | Fwd-able | Globally Reachable | Reserved-by-Protocol |
|---|---|---|---|---|---|---|---|---|
| 169.254.0.0/16 | Link Local | RFC3927 | N/A | True | True | False | False | True |
| 100.64.0.0/10 | Shared Address Space | RFC6598 | N/A | True | True | True | False | False |
Let’s take a look at each in turn.
Those weird 169.254.0.0/16 addresses
‘169.254.0.0/16’, Link Local or sometimes “Automatic Private IP Allocation” (APIPA) is the range of addresses which a device will fall back to when it had neither a statically configured IP address on an interface or a reachable DHCP server from which to request one. You may have seen them in action when you’re enjoying the feeling that comes from forgetting to plug the Ethernet cable in, or not clicking “Connect”, on that new Windows virtual machine. (Just mentioning that for a friend you understand…)
The RFC defines how a device should choose its own Link Local address and what to do if another device is already using it. The things which make this suitable for our use (at least at this point in our assessment) is that those addresses are not globally reachable (just like the RFC1918 addresses), or forwardable. This means that even if they are in use in a Customer’s network somewhere, we should never see them being sent over the WAN to our interconnection.
“Forwardable = False” might be an issue though, as strictly speaking these addresses shouldn’t be forwarded across any routing device, but contained within a single physical or logical network. Arguably, we’re not forwarding them. They’re being allocated to the (translated packets of the) NAT device and then sent on to a local link to another (NAT) device on that same network. With a good legal team, we could probably get away with that in court. However, section 1.6 of the RFC states that “addresses in the 169.254/16 prefix SHOULD NOT be configured manually or by a DHCP server” Wow, SHOULD NOT. It’s not as definitive as MUST NOT, but it is pretty close. Again, we’re not manually configuring or using DHCP, we’re using NAT, so we might get away with that defense.
Back in Part 2 we left a hanging “We can then decide to either leave Alice’s “lake” source address and have the Provider network route all lake addresses back”. Looking at the diagram below, we can see that, if we stick (moderately) closely to the RFC3927, the extent of the Link Local addresses doesn’t get us out of the NAT devices on the interface opposite the intermediate networks. If we use the ‘169.254.x.x’ addresses, we can’t route them past the NAT devices.

On the customer side, this isn’t an issue, because whatever addresses we use in the intermediate network, as packets leave on the customer side, we have to swap back the customer’s real destination (so we can reach their device), and the source address back to the one from their network which they used to represent our service.
However at the Provider end, using those ‘169.254.x.x’ addresses means the “decision” above is kind of made for us. As packets leave the NAT device for the Provider network, we already have to DNAT the real address of the Portal or service in order to reach it. If we leave the ‘169.254.x.x’ source address we used to cross the intermediate network, any router in the Provider network should refuse to forward the packet. I say should, because in some cases it is possible to amend the default behavior of a Linux-based routing device to bend this rule a little.
Possible is not the same as advisable though. We should probably stay away from rule-bending and just NAT both source and destination addresses of the packet as it crosses the Provider network. This does mean that as well as coordinating the NATs in and out of the intermediate network (so which customer WAN gets which 169.254.x.x addresses), we now have to have some RFC1918 addresses on hand to temporarily assign to the customers’ packets as they cross the provider network.
We do need to make sure these temporary addresses are unique within the Provider network, but we don’t have to care about any of the customer networks as these temporary addresses will never be seen beyond the Provider network. Similarly, if the same addresses happen to be in use in a customer network, we’ll never see those beyond the NAT device at the customer side of the intermediate network, so we’re all good on that score too.
Let’s take a look at a packet trace using 169.254.x.x’ addresses. We will need an address in that range for every possible address in the Provider network that a customer will connect to. This could be discrete devices, load balanced VIPs, secondary addresses on devices or similar. We’ll grab the top end of the range for the Provider network. In the intermediate network, ‘169.254.[255].x’ will route to the Provider network NAT device, and there, we’ll assign individual NATs to each endpoint that a customer will connect to.
In this example:
- We’ll make the portal’s real address ‘10.1.1.1’ and hide it behind ’169.254.255.1’ from the ‘169.254.255.x’ range on the intermediate network.
- Customer A is the first customer to ride this roller coaster, so we’ll give them ‘169.254.[1].x’ from the intermediate network address pool.
- Alice from Customer A is back (Yay!) and she’s still ‘10.1.1.1’. She’s connecting to what she thinks of as the Provider’s portal on ‘10.2.2.2’ within the Customer A WAN, that the network engineers (and long suffering PM) have routed to the WAN CE router in the Provider’s DC.
- When Alice is crossing the intermediate network, we’ll swap her ‘10.1.1.1’ source address for ‘169.254.1.1’ . At the same time, we’ll swap the portal’s ‘10.2.2.2’ destination address for its ’169.254.255.1’ intermediate network address.
- As we can’t route these temporary intermediate network addresses across the Provider network, we’ll allocate some Provider addresses to hide them. Let’s stick with the upper end, and allocate ‘10.255.x.x’ and from that ‘10.255.[1].x’ to Customer A and ‘10.255.1.1’ to Alice.
- In the Provider network, we route these new ‘10.255.x.x’ addresses back to our intermediate network NAT device.
- Everything starts with Alice, so she’s on the left, and the Provider is on the right.
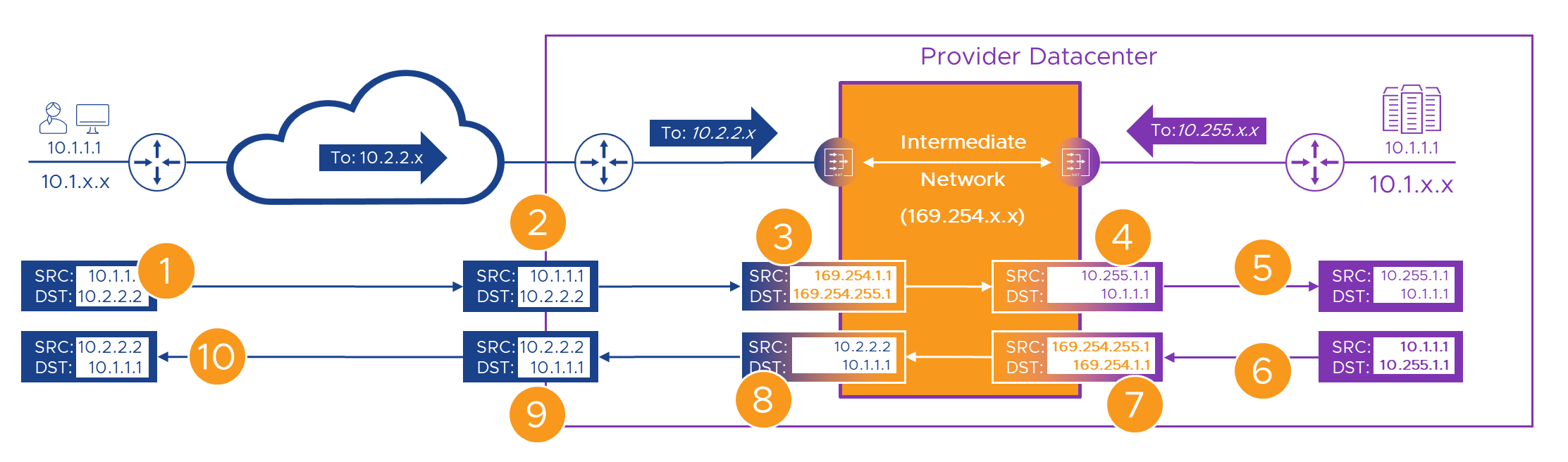
Here’s the flow again, step by step. Fingers X’d that everything still works!
| Step | Action | Result | State |
|---|---|---|---|
| 1 | Alice connects to her WAN’s address for the portal - ‘10.2.2.2’. | The packet with the original addresses in is sent over the WAN. | |
| 2 | The packet, still with its original source and destination addresses arrives at the Customer-A WAN router | The packet is passed to the Provider managed “Customer-A” NAT engine | |
| 3 | On it’s way through, we swap (NAT) Alice’s source (to ‘169.254.1.1’) and the Portal’s destination (to ‘169.254.255.1’) intermediate addresses | The translated packet needs routing to the Provider portal’s intermediate address which only exists on the other side of the intermediate network. | |
| 4 | The packet has its destination NAT’d to the real ( ‘10.1.1.1’) address of the portal and it’s source NAT’d to Alice’s temporary Provider network address (‘10.255.1.1’). | The packet is forwarded towards the portal. | |
| 5 | The packet’s source and destination are unique within the Provider network | The packet routes correctly to the portal | |
| 6 | The portal builds a reply packet using its own address (source) and the Alice’s ‘10.254.1.1’ temporary Provider network address from the received packet (destination). | The packet is forwarded to the Provider NAT engine because of the route we added to the Provider router | |
| 7 | On it’s way back through the Provider NAT engine, the packet has its source swapped to the portal’s ‘169.254.255.1’ and destination to Alice’s ‘169.254.1.1’ intermediate addresses. | As in [3] Alice’s ‘169.254.1.x’ address now only exists on one side of the intermediate network so the packet routes back correctly. | |
| 8 | Before we send the packet back to the Customer-A WAN we need to get rid of all this ‘ |
Once the packet has Customer-A WAN addresses again, it can be sent to the Customer-A WAN router in the Provider DC | |
| 9 | As the packet has Customer-A WAN addresses again, it can be forwarded back to Alice | With Alice’s real destination address, the packets route correctly to her site on the WAN | |
| 10 | The packet is delivered back to Alice’s ‘10.1.1.1’ address, apparently from ‘10.2.2.2’ | The rest of Alice’s connection follows the same sequence |
Woohoo! - Wow, that was an edge of the seat ride for sure!
Okay, so that worked, but there were a couple of sub-optimal elements in there. First, although we didn’t exactly break any rules, we’re not really using those addresses as they were intended in the RFC document. Secondly, we couldn’t route those intermediate addresses across the Provider network, so we had to do yet more NATs. If you remember back to Part 1 all those coffees (or stronger beverages) ago, we said something like “and NAT if you must”. We still must here, but if NATing isn’t great, NATing multiple times is probably worse right? So, having used these RFC3927 addresses as a learning exercise, let’s move on and try find a better solution.
What the heck is a 100.64.0.0 addresses and just how big is a /10
What would be really cool would be if somebody had realized that with the advent of mass IPv4 adoption, there would be times when different networks would crash into each other, and worked out a way to make it less painful. Enter RFC6598 stage-left (or is it just Tom Cruise with another disguise?). Shared Address Space or, “Carrier Grade NAT” (CGN) as it’s often known, is a reservation of IPv4 addresses put aside for Carriers (or Providers in our case) to slip in between large networks whose native addresses can’t be used directly. Sounds familiar right? Well, once again, we’re not quite sticking to the letter of the law RFC here. There’s a note in the Introduction of RFC6598 which says:
Now we might have that (see Don’t and say we did in Part 2), but in these examples, we’re working on the basis that we can’t do all our NATing in one place because of that order of operation gotcha that we found. However, our issue is still pretty much the same, so we’ll roll with it for now, work on the assumption that that note was a capability constraint rather than a functional requirement and hope nobody notices…
Okay, so what are the advantages of using these addresses instead of the Link Local ones in the last section? Well, for one, there are lots of them, err.. addresses that is. To answer the “just how big is a /10” question, the range goes from ‘100.64.x.x’ right up to ‘100.127.x.x’! Whichever way you slice and dice that, it’s a lot of addresses. We’ll look at allocating chunks of address space in more detail soon, but for now, you could allocate an entire /16 to over 60 different sites, which would give space for more than 60,000 individual Alices, Bills and Peters, in each site!
The second advantage is that, as per the table above, although not “Globally Reachable” these addresses are “Forwardable”. That makes them more like RFC1918 addresses than those ‘169.254’ addresses, in that the Provider can route them around their network, but they can’t be used over the Internet. Or, at least we’d hope, coming in from a customer’s WAN. That means that where, in the last example, we had to take customer traffic, NAT it to Intermediate Network addresses, then NAT it to Provider temporary addresses (because Link Local addresses shouldn’t be forwarded), using these ‘100.64’ addresses means we can skip that last NAT. If we sed s/169.254/100.64/ that last packet flow example, we’ll end up with this.
- We’ll make the portal’s real address ‘10.1.1.1’ and hide it behind ’100.64.255.1’ from the ‘100.64.255.x’ range on the intermediate network.
- Customer A is the first customer to ride this roller coaster, so we’ll give them ‘100.64.[1].x’ from the intermediate network address pool.
- Alice from Customer A is still here, and she’s still ‘10.1.1.1’. She’s (still valiantly) connecting to what she still thinks of as the Provider’s portal on ‘10.2.2.2’ within the Customer A WAN, that the network engineers (and long suffering PM) had long ago routed to the WAN CE router in the Provider’s DC.
- When Alice is crossing the intermediate network, we’ll swap her ‘10.1.1.1’ source address for ‘100.64.1.1’ . At the same time, we’ll swap the portal’s ‘10.2.2.2’ destination address for its ’100.64.255.1’ intermediate network address.
As we can’t route temporary intermediate network addresses across the Provider network, we’ll allocate some Provider addresses to hide them.We don’t need to do this as we can forward CGN addresses.- In the Provider network, we route these ‘100.64.x.x/10’ addresses back to our intermediate network NAT device.
- Everything, as usual starts with Alice, so she’s still on the left, and the Provider is still on the right.
Okay, let’s take a look at the new packet walk…
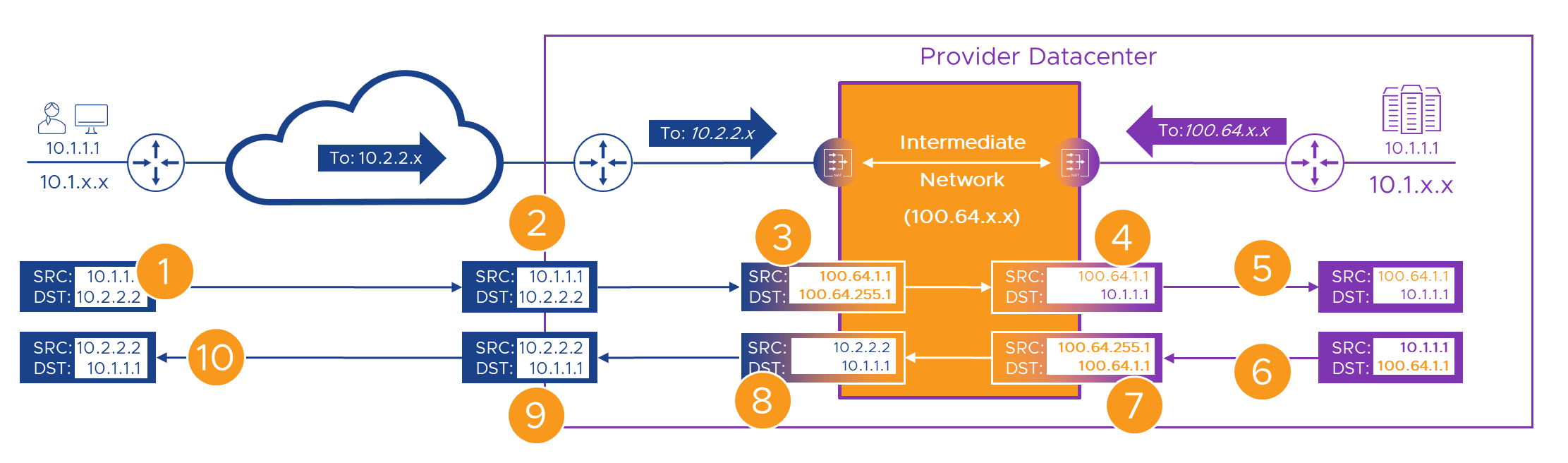
Here’s the flow again, step by step, hopefully for the last time! Fingers X’d that everything still, still works!
| Step | Action | Result | State |
|---|---|---|---|
| 1 | Alice connects to her WAN’s address for the portal - ‘10.2.2.2’. | The packet with the original addresses in is sent over the WAN. | |
| 2 | The packet, still with its original source and destination addresses arrives at the Customer-A WAN router | The packet is passed to the Provider managed “Customer-A” NAT engine | |
| 3 | On it’s way through, we swap (NAT) Alice’s source (to ‘100.64.1.1’) and the Portal’s destination (to ‘100.64.255.1’) intermediate addresses | The translated packet needs routing to the Provider portal’s intermediate address which only exists on the other side of the intermediate network. | |
| 4 | The packet has its destination NAT’d to the real ( ‘10.1.1.1’) address of the portal |
The packet is forwarded towards the portal. | |
| 5 | The packet’s source and destination are unique within the Provider network | The packet routes correctly to the portal | |
| 6 | The portal builds a reply packet using its own address (source) and the Alice’s ‘100.64.1.1’ intermediate network address from the received packet (destination). | The packet is forwarded to the Provider NAT engine because of the route we added to the Provider router | |
| 7 | On it’s way back through the Provider NAT engine, the packet has its source swapped to the portal’s ‘100.64.255.1’ intermediate address, but its destination is already/still Alice’s ‘100.64.1.1’ intermediate address. | As in [3] Alice’s ‘100.64.1.x’ address now only exists on one side of the intermediate network so the packet routes back correctly. | |
| 8 | Before we send the packet back to the Customer-A WAN we need to get rid of all this ‘intermediate network’ stuff, so we NAT both source and destination addresses | Once the packet has Customer-A WAN addresses again, it can be sent to the Customer-A WAN router in the Provider DC | |
| 9 | As the packet has Customer-A WAN addresses again, it can be forwarded back to Alice | With Alice’s real destination address, the packets route correctly to her site on the WAN | |
| 10 | The packet is delivered back to Alice’s ‘10.1.1.1’ address, apparently from ‘10.2.2.2’ | The rest of Alice’s connection follows the same sequence |
Woohoo! - Wow, err.. actually, I’m not sure that’s quite as exciting twenty-seventh time around. But at least it still worked!
Industrialize and scale
Both the Link Local and Carrier Grade NAT (Shared Address Space) methods seem to work. The CGN one is slightly slicker as we don’t need to allocate, coordinate and configure the second set of NAT addresses but hopefully it’s clear how they both work in essentially the same way. In the Provider world, half the battle is getting something to work, the other half is getting it to work repeatedly. The third half of the battle[sic] is getting it to bill correctly, but that’s a (half a) battle for another day. Repeatedly involves things like hardware and software scaling, creating a configuration model that lets us easily create identifiers like names and IP addresses that take the “design” out of adding extra customers. Things like:
- Device names will be [device-type]-<pod-no>-<device-no> so each time we add a new one we just bump <device-no> by one.
- Each tenant will be allocated a <some-size> range of IP addresses for their [whatever] network connection from this [pre-allocated/reserved] range/pool, so each time we do this, we get the next <some-size> block from the pool.
- Each tenant will be allocated <some-number> of VLANs for L2 connectivity from this [pre-allocate/reserved] range, so again, each time we onboard a new tenant, we know what their VLANs will be.
If you’re really dedicated/lazy you can create a Slack bot (or a spreadsheet) that will take a tenant “number”, and use it to calculate all those per-tenant configuration elements. Or, take a tenant number as an input to a vRealize Orchestrator workflow that will do the hard work for you. Anyway, more digressing. Let’s try and scale that last example and see if it still works.
Remember, now we’re experts, every customer uses the same IP addresses, and we want to use the same model over and over again (because lazy err… repeatable, is good)! Okay, without the aid of a safety net (and slightly regretting using orange for the intermediate network as it’s very bright ), here’s the multi-tenant version of the packet flow(s).
Although we show per-tenant flows on the right hand side of the intermediate network, there’s only a single Provider NAT device (stretched here to show it affects all customers). We can get away with just having one because it’s only responsible for NATing between the Provider’s real and intermediate addresses. It doesn’t need to do anything with Customer/Tenant addresses as they get taken care of on the per-Tenant NAT devices on the other side of the lake… err intermediate network.
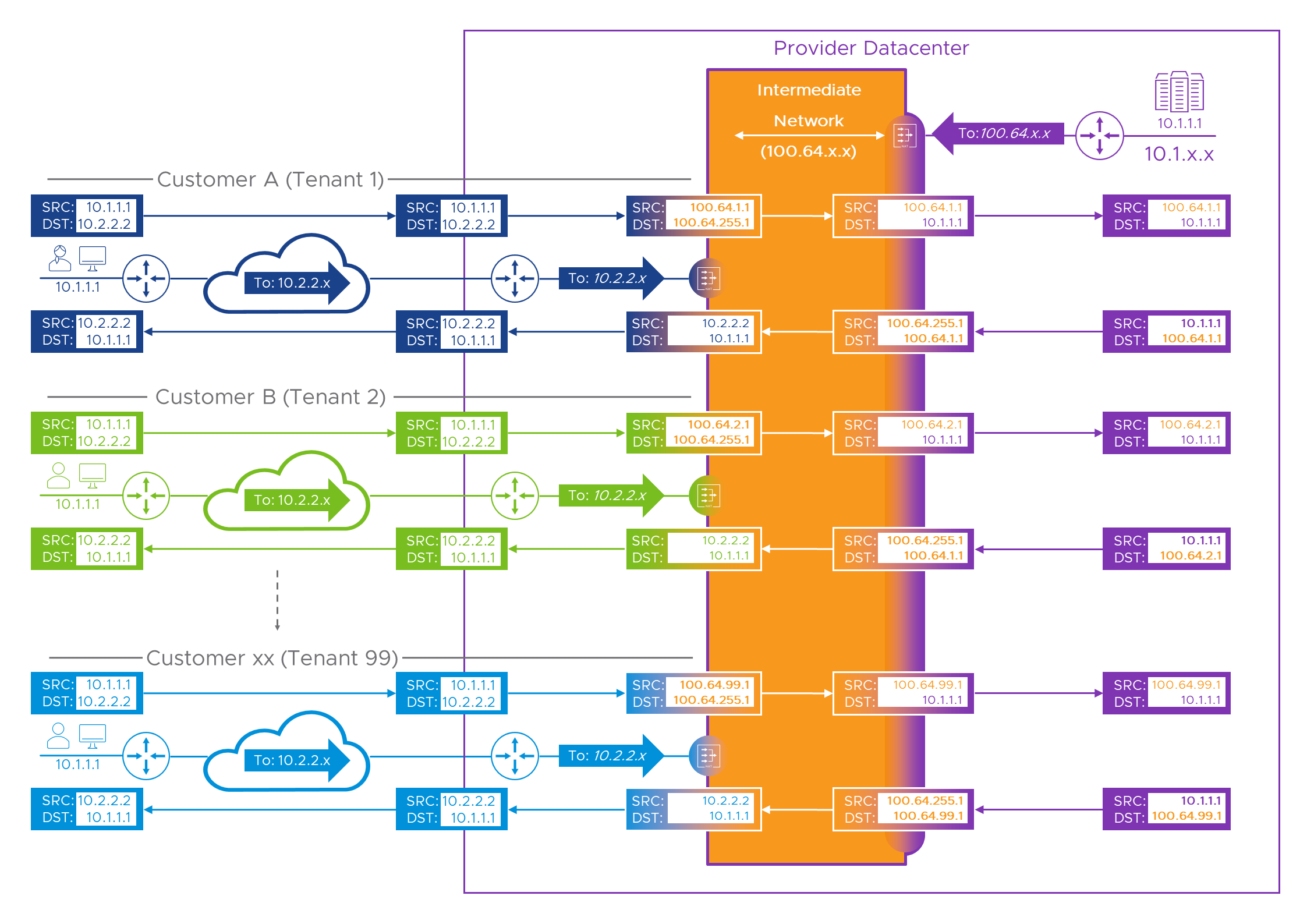
Hopefully this makes sense if you slogged through all the earlier examples. Let’s look at what we had to change to make this multi-tenant ready, and what we managed to leave alone.
- We’ve allocated each customer a /24 of CGN NAT addresses. As before, Customer A (Tenant ID: 1) gets ‘100.64.[1].x’ or, ‘100.64.1.0/24 if you prefer. Depending upon the number of connections from a given customer network and the specifics of the NAT (or PAT) device this may be way overkill. But, operationally, knowing which customer a connection is from just by looking at one octet in the source IP address can be really useful.
- Customer B (Tenant ID: 2) gets ‘100.64.[2].x’ or ‘100.64.2.0/24. The last octet (the “dot 1”) would be allocated pseudo-randomly depending on the configuration of the NAT device and the number of other connections from Customer B, but we’ve cheated a little for the sake of clarity here, so we see Bill (from Customer B) as ‘100.64.2.1’.
- At the bottom of the diagram we see… Oh, somebody new. Let’s call him Nigel from Tenant ’ninety-nine’ (You can go with Xavier from Customer ‘xx’ if you prefer). Just to show how we scale, Nigel’s WAN is allocated, you’ve guessed it: ‘100.64.[99].0/24’. Again, for clarity we’ve cheated and given Nigel the “dot 1” so he becomes ‘100.64.99.1’.
And, that’s about it. As our successive customers get allocated higher and higher ID numbers, we still go through the same process for each one. The portal or service sees all its WAN connections from neatly managed ‘100.64.some.thing’ addresses, and simply routes all of that range back to the Intermediate network. That third octet goes all the way from ‘1’ (well, zero really, but if you have to use that, make sure any “algorithm” you create for naming or numbering stuff doesn’t break in the presence of a zero value) to ‘254’, because we used ‘100.64.255.0/24’ for the Provider’s devices and services. This might be enough to reach the design limit/maximum in which case, Go Us! But it might not be if we have bigger plans (Muhahahaha!).
Divide and Conquer
We can easily scale to higher numbers of customers/tenants if we have to meet that requirement. As we saw earlier, there are a lot of addresses in the CGN range. We could treat each ‘site’ as an isolated island (oh no, more lake analogies) and never route the CGN addresses out of a given location (on our Provider internal WAN). If that is the case, we can happily use the same address model with exactly the same addresses in every site. That does make it kind of awkward if anyone changes their mind and decides to route between customers and portals in different sites.
A safer model (as far as the Architect’s ability to say “I thought you’d want to do that, so I designed it in already”) would be to plan to (be able to) route between sites even if you don’t think you need to, at least not to begin with. Depending upon how many connections you expect per tenant, how many addresses you want to reserve for each tenant, and how many tenants you want to scale to, will tell you how many addresses you need per “site”. How many sites you want to design for will then give you the building blocks of a formula to carve up your chosen intermediate address space. Using the same address space, but distributed across Provider sites allows us to route between them if we want to.
Let’s take a look at how we could slice’n’dice the CGN address space. Here’s the range again, with some extra details for clarity.

We could, for example, decide that one /16 (entire second octet) is big enough for a site, and that the 60-ish /16s in the ‘100.64.0.0/10’ subnet is also enough for the number of sites we’ll need. Then, our site allocation model would be something like:
Customer number: 1 to 254 [ID] (per site)
Let’s take Site number and bump it by 63 for the >=64, 2nd octet range
Provider Subnet: 100.(63+[site]).255.0/24 (per site)
Customer Subnet: 100.(63+[site]).[ID].0/24 (per customer, per site)
At the other end of the scale, we could decide that each customer only needs a single IP address and that Port Address Translation (AKA Dynamic PAT or Overload / Hide NAT depending on your NAT device vendor) will do the job. If that’s the case, the formula above looks like this. The single intermediate network address could be the one assigned to the interface of the NAT device or it could be a separate address used just for NAT.
Customer number: 1 to 254 [ID] (per site)
Again we need to bump the Site number by 63
Provider Subnet: 100.(63+[site]).255.0/24 (per site)
Customer Subnet: 100.(63+[site]).[0,1,2 etc.][ID]/24 (per customer, per site)
The likelihood is, that a /24 for each customer is overkill. Similarly, a single address will probably work, but might, on a bad day, lead to ‘port exhaustion’. We will probably end up with something in between the two extremes. Some network devices make it easy to specify a pool or range of addresses for things like NAT, so we could allocate an arbitrary number of addresses to each customer. Some prefer subnet sized blocks, so we can only assign binary powers so 1,2,4,18,16 etc. NAT addresses per customer. The device doing the NATing will determine what we have to work with here.
Knowing how many individual addresses we need for each customer will then define the minimum size we should allocate, but we may choose to allocate more for operational simplicity. Exactly how this should be done is something for the detailed design stage of a project.
Name names for goodness sake
All throughout this looooong post there have been references to “NAT device”, “NATing device”, “Provider NATing device”, “per-Customer/Tenant NAT device” and similar, but what the heck are these really? Are they firewalls? Are they routers? Load balancers? What? Well, the answer is “it depends”.
Yes, sorry, I know…
The thing is, it does depend. There are solutions doing this kind of thing using big switches to create a VRF per tenant and then handling the NAT there. That’s great if you have the licence for the feature and don’t have to pay per tenant for a separate context or virtual appliance licence. You could do this with a Linux VM (per tenant/provider of course) using the native kernel routing capabilities or a ready-made router virtual appliance. You could use NSX-V Edges or any one of a myriad network devices that allow some sort of virtual routing and forwarding separation or similar.
Hopefully though, the models explored in this series of posts will help whatever network device you have at your disposal. Often. as with many “which is best” technology-based questions, the answer is “the one with which you’re most familiar”.
Summary
- To pass as a network engineer remember, Route if you can, NAT if you must!
- NAT is not safe to use if the same addresses might appear on either side of the NATing device.
- As per RFC6598, some NATing devices can cope if they see the same addresses on either side (but it’s best not to rely on that unless you know for sure yours can).
- Filter, NAT, Route or NAT, Filter Route? The order of operation within a network device can bite you if you’re not careful.
- Even if the order of operation works in your favor, what would happen if somewhere down the line, somebody upgrades your solution with a device that has a different order of operation?
- When connecting networks whose administration lives within different groups and cannot be guaranteed to play nicely, design for the worse case and you’ll look like a hero when it still works!
- If you’ve read all three posts, you’re now carrying, in total, over 10,000 words of NAT stuff in your head, and probably need a drink and a lie down.
If you made it all the way down here, thanks for persevering! Hopefully you’ve found this series of posts useful, or at least mildly interesting. If you have any comments or questions, please feel free to use the comments section below.
I’d also like to give a huge shout out to my good friends Daniel Paluszek, John Marrone and Grant Markham for reviewing these posts and, The Inti Shah for teaching me to use sub-optimal instead of “you could have done that better!”
In case you were wondering, that's around 5427 words of your life you'll never get back..!
Feel free to share this post...
See also
- Multi-Tenant WAN Access to Shared Resources: Part 2 - A Solution
- Multi-Tenant WAN Access to Shared Resources: Part 1 - The Problem
- Multisite vCloud Director With Global Load Balancing
- Cross OrgVDC Networking in vCD 9.5